全体像
- 機能としてはCPUのキャッシュに相当しますが、レイテンシよりもスループットを優先するため、比較的タイミングに余裕を持たせた構造に置き換えることができます。これは、回路規模を抑制するとともに、プロセスに依存しない[1]コンパイラブルな通常の論理記述で設計できることを意味します。
- 制御タイミングに余裕が出てくると、FIFOと結合を用いて容易にデータの流れをコントロールすることが出来ます。FIFOはデータもしくは命令キューとして働きます。FIFOの深さをパラメータとして与えることにより、性能・コストに対して柔軟なモジュールを作り上げることが出来ます。
- キャッシュで重要な実装部分は、タグの参照と更新部分になります。タグはキャッシュラインのValid, Modify, Address(上位アドレス)を含み、アクセスの度に参照され、どういったデータ処理をすればいいかの条件になります。その判断結果をFIFOに送り、パイプライン処理することによりタイミングを自動的に吸収することにします。パイプライン処理により、Non-blockingアクセス[2]が実現できます。
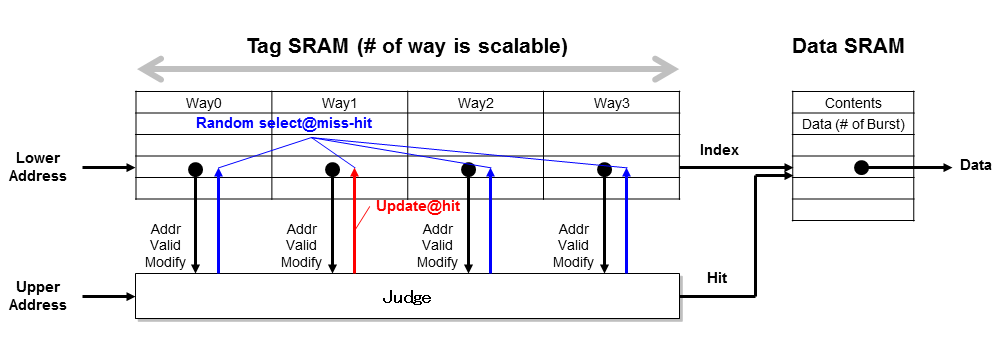
- タグはキャッシュの型(Direct-map, Set-associative, Full-associative)により構造が変化します。Full-associativeは小規模キャッシュに有効ですが、エンジン用には非効率的なので扱わないことにします。Direct-map, Set-associativeの違いは、Way数が1かそれ以外かの違いになるため、基本的にSet-associativeを考えておくと包含できます。
- Wayをサポートすると、Index(アドレスの下位)索引でWay数分の情報を管理することになります。また、キャッシュの置き換え時にどのWayを使用するかのアルゴリズムも決定しなければなりません。キャッシュ容量を大容量して性能を稼ぐ方がエンジンのメモリアクセスに合致するため、簡単化できるランダム置換方式にします。
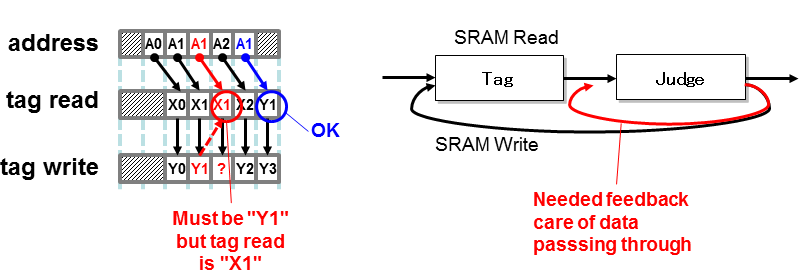
- タグは上記の判断結果と同時に、即時に更新されなければなりません。即座に更新しないと、その次のアクセスが更新前のタグを参照して誤った動作をします。このことは、参照・処理・更新を1サイクルで実行しなければならないことを意味しています。動作周波数のボトルネックなるこの部分は、タグの数とR/Wのサポートの有無によっても影響します。
- ところで、大容量のキャッシュになるとタグをSRAM化して回路規模を抑制する必要が出てきます。タグの参照・処理・更新は逆に1サイクルではなく、Nサイクルで実施しなければなりません[3]。見かけ上は1サイクル、SRAMへはNサイクルで更新するための対処(パイプラインフィードバック:準備中)が必要です。これは、自動的に論理深度の分散も図ることになります。
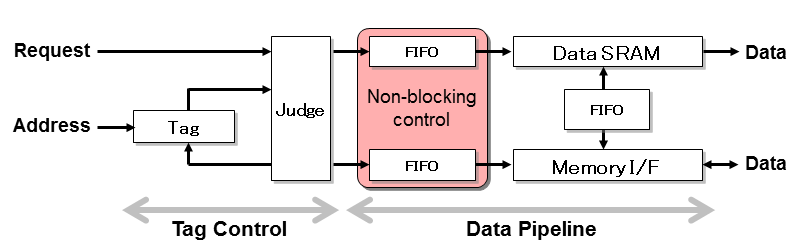
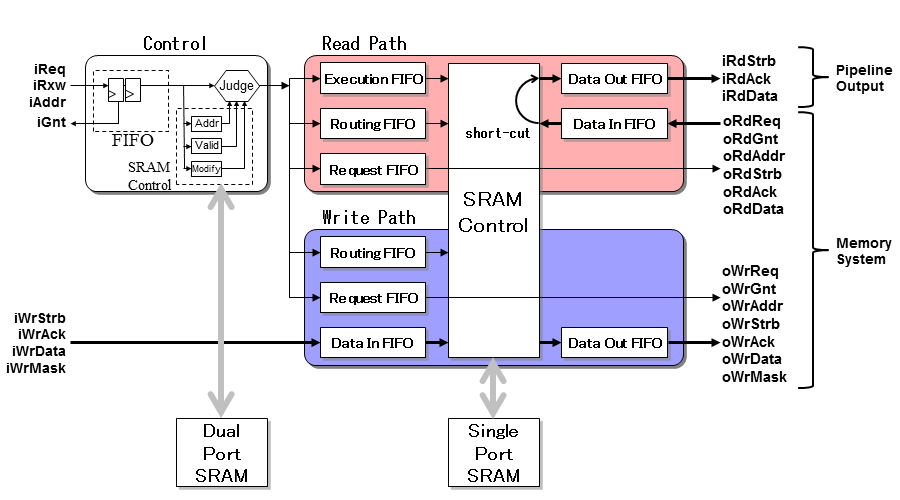
- メモリ接続で述べたように、リクエスト制御, Read制御, Write制御にパイプラインは分かれます。ターゲットのメモリシステムが内部のSRAMと外部のSDRAMの2つ存在することから、さらに細分化が必要です。基本的にデータはSRAM(いわゆるキャッシュの中身)を中継することから、SRAMを中心に考えた方がよさそうです。
- SRAMはタグ用とデータ用の2つが必要です。タグ用のSRAMは、読み出しと書き込みを同時に行わないと性能劣化するため、2ポートタイプを選びます。一方データ用のSRAMは、大容量化を考えると最も廉価なシングルポートタイプを選んだ方が経済的です。ただし、キャッシュフィル(書き込み)とキャッシュヒットによるデータアクセス(読み込み)が同時に起こると、いずれかをブロックするため性能劣化に繋がります。小規模であればこの状況が生じやすいので2ポートタイプを、大規模であれば逆に生じにくいのでシングルポートタイプを選べばいいと言うことになります。
詳細ブロックについて
- 全体像をまとめたブロック図を示します。
- 前段のControlは、タグ制御と後段のFIFOへの命令発行を行います。ここで、Wayなどキャッシュの構造に依存する制御を完結させます。判定部分では、入力するアドレス・R/Wの種別と索引したタグ情報および後段のFIFOの状態(Busy信号など)からサイクルごとに状態を決定します。ステートマシンになりますが、専用の状態を表すレジスタはなく、前述したタグの内容やFIFOの状態がその代わりになります。
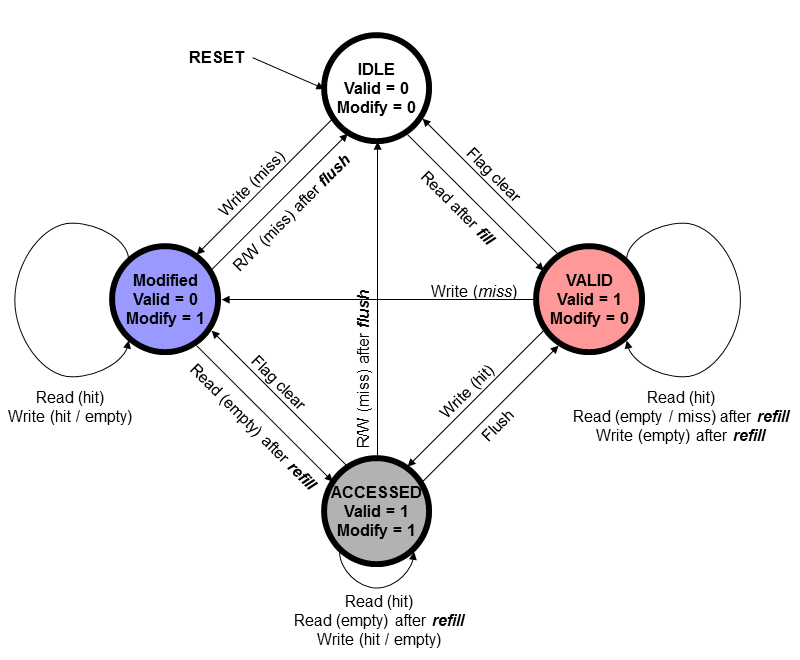
- タグは通常のアクセスの他に、Flush(Write-backデータの書き戻し)とClear(タグを初期化)のサポートが必要です。通常アクセスのサイド信号として加えたり、通常アクセスに同期しない別の非同期制御で個別に制御したりします。これらは判定部で一括処理します。
- ValidとModifyフラグで状態を表す簡単な状態遷移図を示します。この中で"empty"とあるのは、キャッシュライン(バースト分)は有効だがアクセスすべきワードが無効であることを示しています。これは、Write時に一旦キャッシュラインをRefillしてWriteするのではなく、Writeした部分だけを有効にして必要に応じてRefillする方式を採用していると生じます。詳細は複雑になり本質でない説明になるため割愛します。
- 後段のパイプラインは、データSRAMを中心にR/Wで分離したFIFO群で構成します。R/Wの制御は非同期に実施し、唯一SRAM部分でアクセス競合が生じる場合にのみ両者の調停を行います。調停順序は簡単化のためOut-of-orderにしますが、前段のContolが必ず整合性を保つように制御することで問題ありません。
- Read Pathの各FIFOの設置理由は以下の通りです。
- Execution FIFO
ヒット・ミスに関わらずアクセスを貯めこむために設置します(Non-blocking対応)。このFIFOがないと、前段のControlがStallし結果としてマスター側がブロックされます。FIFO深さは、ミスしてメモリアクセス行うことにより生じるレイテンシ期間の間にいくつのアクセスを吸収するかで決定します。
- Routing FIFO
ミス時にSDRAMなど外部メモリへのアクセスを行うと、必ずレイテンシが発生します。データが実際返って来るまで、データSRAMに対するアドレスを保持するために設置します。FIFO深さは、Execution FIFOとほぼ同じ考えで決めますが、バーストアクセス単位の設定なので小さくします。
- Request FIFO
同期(同期FIFO A)で示したように、ここはタイミングアークを切断するためだけに設置します。FIFO深さは、最小の2にします(外部メモリとの接続タイミングに余裕があれば不要)。
- Data In FIFO
外部メモリから返ってくるデータをバッファリングするために設置します。バーストReadアクセス時の途中のハザード(Waitの発生)を回避します。データSRAMに無条件にデータを書き込みできるのであれば不要ですが、キャッシュ出力をマスターからブロックしたり、シングルポートSRAMでR/W競合が生じたりすると、外部メモリに対するWaitを発生させてしまいます。なお、外部メモリに対し、バースト途中であってもWaitできるのであれば必ずしも必要ではありません。ただし、外部メモリが他のシステムと共有化していると、このようなStallはシステム全体に性能劣化の影響を及ぼします。FIFO深さは、バースト長に比例し、バーストをいくつ保持するかで決定します(通常このFIFOがフルになる可能性があれば、Requestをブロックします)。
- Data Out FIFO
マスターへ返すデータをバッファリングするために設置します。FIFO深さは、マスターのStallする頻度に応じて決定し、そのゆらぎを吸収することでキャッシュ全体のStallの発生を回避します。マスターがStallしなければ不要です(ReadデータをWaitなしで常に受け付け)。
- Write Pathの各FIFOの設置理由は以下の通りです。
- Routing FIFO
Readと同じですが、Readと違ってWriteレイテンシは0に近づくためFIFO深さは小さくします。
- Request FIFO
Readと同じです。
- Data In FIFO
ReadのData Out FIFOに類似します。マスターから書き込むデータをバッファリングするために設置します。FIFO深さは、マスターのデータアクセスの頻度に応じて決定し、そのゆらぎを吸収することでキャッシュ全体のStallの発生を回避します。マスターが常に連続アクセスするのであれば不要です。
- Data Out FIFO
ReadのData In FIFOに類似します。外部メモリへ書き込むデータをバッファリングするために設置します。SRAMと外部メモリに対するWaitの考え方もReadと同じです。
- 上記のFIFOが全てSRAM I/Fに接続されているのが分かると思います。即ち、FIFOはSRAM I/Fの記述する部分で結合ルールを用いてカップリングします。この時シングルポートSRAMの場合であれば、より集中した接続となり、2ポートSRAMの場合であればR/Wに分離した接続になります。
- キャッシュ自体のレイテンシ性能を向上させるため、Read PathのData In FIFOの出力とData Out FIFOの入力をデータSRAMを介することなくダイレクトに接続することも考慮します(Short-cut)。ただし、外部と内部の周波数や語長に差があると、単純には接続できないので注意が必要です。
最小構成のキャッシュについて
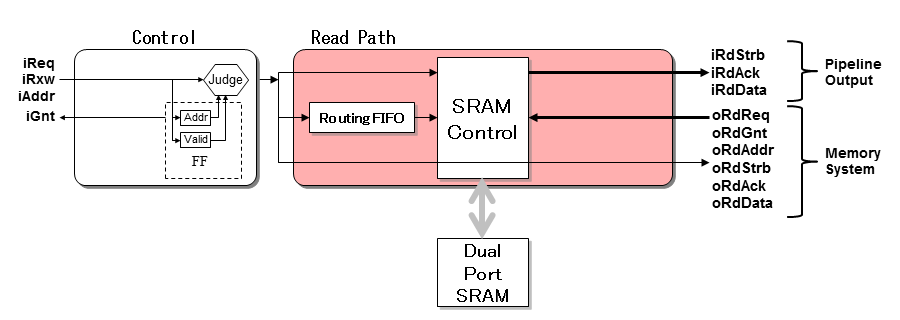
- まともに上記仕様のキャッシュを作成すると、分量もさることながら理解しきれなくなるので、最小構成のキャッシュを考えてみます。
- 前ページで示したDestination Baseの処理を考えると、Readアクセスの重要性から、少なくともR/WキャッシュでなくともReadキャッシュだけでも意味があります。Readに限定すると、タグ管理が簡素化するとともにデータパスも半減します。
- 次にキャッシュのWay数を1(Direct-map型のキャッシュ)に限定します。エンジンを接続するとして、画像などインクリメンタルなアドレッシング処理を行うだけとすればこれで十分です。
- さらに、必要不可欠なFIFOだけに絞り込みます。Request FIFOとData Out FIFOは、回路負荷(遅延)が危険でなければ削減できます。同様に、マスターI/FのFIFO(言及していないがタイミングアーク切断用)も削減します。
- Data In FIFOは外部のメモリの仕様次第ですが、バーストにハザードが入っても問題なければ不要です。また、Execution FIFOはNon-blockingのため重要ですが、あえて有り無しの比較のため削除します。
- Routing FIFOはだけは、メモリレイテンシを吸収しないと毎アクセスペナルティが発生するため実装します。
- 小規模キャッシュに限定して、タグ用のSRAMはFFに置換します。FFにすることで、SRAM特有の複雑さが解消します。データSRAMはSRAMを使用しますが、同様に小規模キャッシュに限定することから2ポートSRAMにします。
- 最後に、ショートカットなども実装しないことにします。上記の条件により、図のような構成になります[4]。
パラメータおよびインターフェイス
- 汎用的なキャッシュにするためには、キャッシュ容量やWay数、上記のFIFOの深さ(レイテンシ吸収度)を可変にしておく必要があります。ここでは例として、キャッシュ容量とバースト長を可変にできるようにします。FIFO深さや語長は固定します。
- マスターインターフェイスは前ページで述べた通りにします。一方、キャッシュのタグ操作用のインターフェイスは、最小のものを定義します。ここでは、全キャッシュ領域のタグのクリアを行うことにします。タグはFFで構成することから、1サイクルで処理できマスターに影響を与えません。また、リセット時にクリアできることから、初期化の必要がなくなります(タグがSRAMだとキャッシュを使う前に初期化が必要になる)。インターフェイス自体も簡単でRequest信号とGrant信号だけで十分です。
回路デザイン > 設計例 [キャッシュ] > 実装にあたって 次のページ(コーディング) このページのTOP ▲