目的
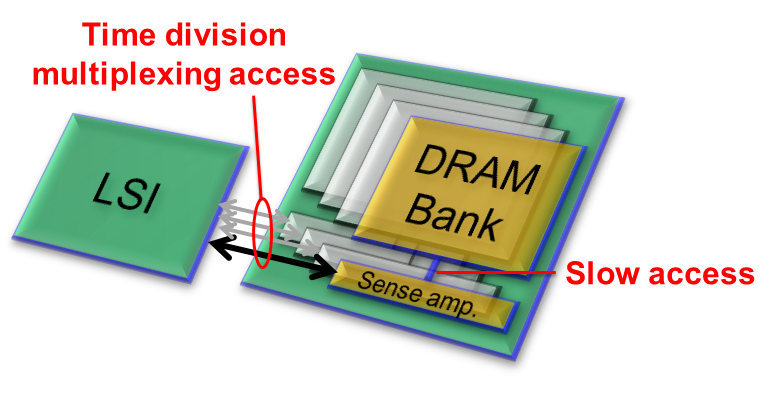
- 大容量で廉価なSDRAM DDR(SDRAM Double Data Rate以下DDR)は、近年の大量データ処理にあってはなくてはならぬ存在です。ご存じの通り、DDRは1つのコマンドで大量のデータを内部に確保し高速なバーストアクセスでチップ間通信を行います。コマンドの発行間隔は長いのですが、メモリセルを複数バンク存在させることで複数コマンドのオーバーラップを許しスループットを確保しています。
- 従って、DDRの高いスループット性能を引き出すには、DDRに合った制御が必要になります。FPGAではツールで自動的に設計してくれるのですが(最適かどうかは不明)、ここであえて論理設計をしたいと思います。以下に、いくつかの課題を上げます。
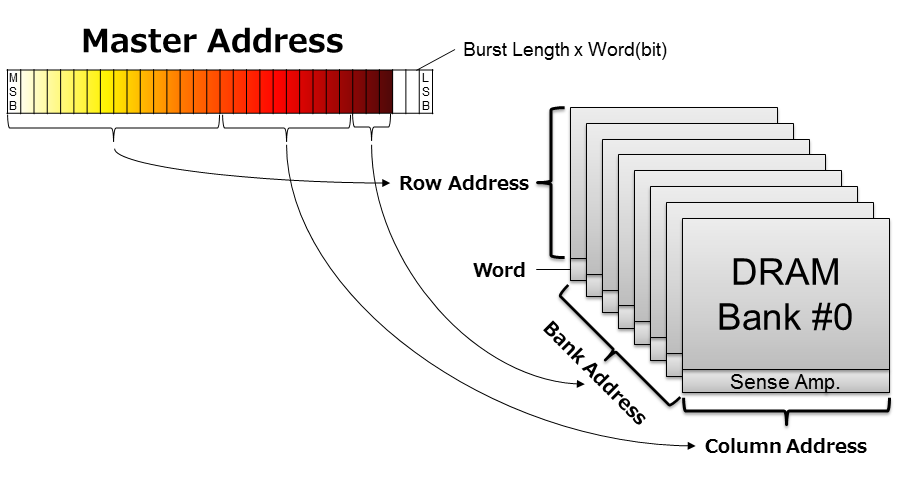
- 1番目の課題は、ランダムアクセスに有効なアドレスマッピングの与え方です。基本的に、マスターアドレス[1]からDDRアドレスへの変換は、ほとんど回路を挟まずに割り付けます。問題は、DDRアドレスはその構造に直結するRow, Column, Bankに分解できますが、マスターアドレスのどのbitをどこに割り付ければいいかです。
- 2番目の課題は、連続するデータアクセスは上記の隠蔽機構により最大性能が引き出せますが、ランダムなデータアクセスは無効期間が発生するため、ペナルティとなって性能劣化することです。ランダムアクセスの制限はチップ内の機能モジュールの構造[2]を大きく左右するため重要です。ここでは、ランダムアクセスに制限を付けつつも、性能劣化させないポイントを述べたいと思います。
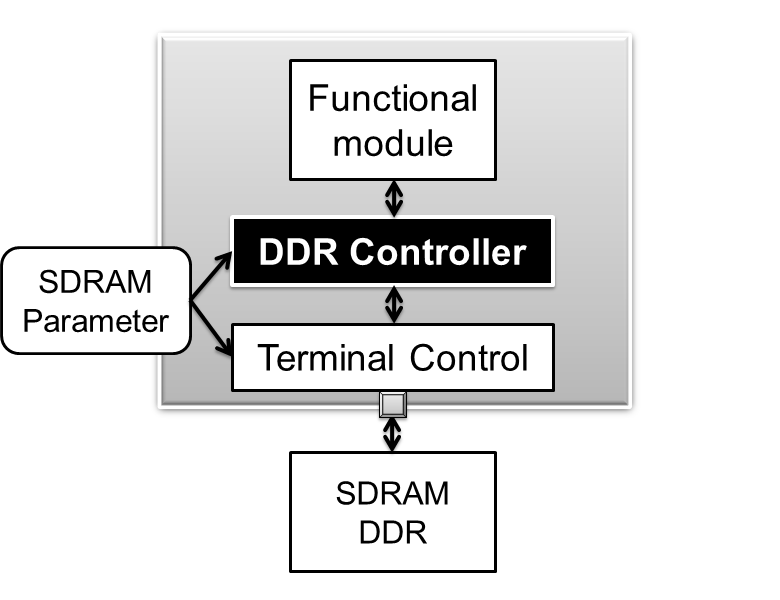
- 3番目の課題は、DDRはRawデバイスなので、上位の機能モジュールとハンドシェークができるマスター用のインターフェイスを用意しないといけないことです。また、アクセスタイムなどDDR固有の制御を隠蔽して行わなければなりません。DDRインターフェイスはDDRの規格通りにするとして、パラメータの与え方を述べたいと思います。
- 4番目の課題は、高速なバーストアクセスは高価な端子を少なくする効果はあるのですが、反面端子のアナログ的な制御とチップ内部との周波数差の吸収が必要になることです。周波数差はサイジング付きの非同期FIFOで解決できますが、端子制御は個々のチップに依存するものなので一般解はありません。DDR制御(実装)で、FPGAへのマッピングをサンプルとして別途述べますので、それを参考にして頂きたいと思います。
- なお、DDRにはバージョンがありますが、速度、機能制限、端子の別活用などの差で、大きく変わるものではありません。基本的に統一した設計思想で対応できます(場合によっては回路自体も共用可能)。
考え方(ランダムアクセス)
- DDRクロックは速くなる方向なので、それに耐えうるよう回路の単純化が必要です。DDRは様々な操作ができますが、全てを使う必要はありません。与えた条件を満足しながら厳選することが大事です。
- 先ず、ランダム性能を考えます。DDR性能は、データバスをフルに使用している状態で最大化します。この条件は、規定される最小バースト長がランダムアクセスの最小単位であることを意味します(これ以下だとデータバスに空白が生じる)。DDR2は4、DDR3は8と異なっています。
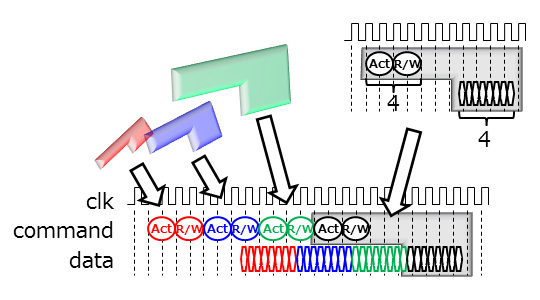
- 一方、DDRへのコマンドはランダムアクセスが前提なら、ActivateとR/Wの2つのセットが必要です。ACタイミングの規定により、コマンド間に1サイクルのNOPを挟むことを前提にします。つまり、4サイクルが最小単位になります。これは上記のバースト長が8(DDRなので半分にすると4)の場合に合致します。ここではこの4サイクルのコマンドとデータアクセスをプリミティブとして制御を組立てることにします。
- 当然、R/Wのレイテンシは異なります。上図のように単純にマッピングするとデータがぶつかります。そのため、R/Wの切り替わりはデータが重ならないよう(さらに経年劣化しないようさらにTurn-aroundの1サイクル加えて)、コマンド間にNOPを挿入[3]します。
- 上記をまとめると、ランダムアクセスの最小単位はWordの語長x8になります。これ以下だとアクセス効率が下がります。話は逸れますが、PCで使われるDIMMは64bitです。つまり64Byte(8Byteが8バースト)が最小単位です。この単位を一度に使入れないと無駄になります。しかしCPUやGPUにはキャッシュがあり[4]、この要請を回避しています。機能モジュールにおいても、次で説明するキャッシュの組み合わせが一つの解と言えます。
- ところで、Activateの後にはPre-chargeが必要[5]です。しかしこのコマンドを挿入するとせっかくの4サイクルが6サイクルになってしまいます。ここで同一バンク、同一Rowアドレスをアクセスするページ機能を見限り[6]、アクセス終了後自動でPre-chargeを行うR/Wコマンドを発行することにします。
考え方(アドレスマッピング)
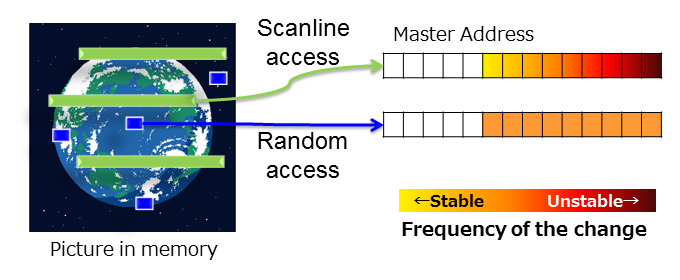
- 一般的に、小さな単位を繰り返して処理すると、メモリアドレスの変化の頻度は、LSB寄りの方が高くなります。ランダムは非定常状態であるとすると、LSB寄りのアドレスがランダムな変化をすると言うことになります。
- 前述のランダムアクセスの考えは、小さなアクセス単位が連続してもペナルティがないことが前提です。それは即ち、小さなアクセス単位ごとにバンクが異なり、アクセスが重ね合せられると言うことです。
- この条件に従うと、バンクアドレス(Bank)には、LSBから数えて4サイクルの最小単位の次のマスターアドレスを割り当てることになります。また、カラムアドレス(Column)にはその次のマスターアドレスを、ロウアドレス(Row)にはさらにその次のマスターアドレスを割り当てることになります。
- ここで重要な注意点を述べておきます。この解は万能ですが、最適解ではありません。アプリケーション(マスターの振る舞い)によってアクセスパターンが偏る場合、その偏り方に最適なアドレスの割り付けが存在します。例えば、同じスキャンラインアクセス(X,Y,Z軸の走査など)でも、1次元の横方向、2次元の縦方向、そして3次元の奥行方向のアクセスの単位は大きく異なります。また、複数マスターが異なる上位アドレスに対してシーソーアクセスすることもあります。下手をすると、同じバンクアドレスばかりアクセスすることになるかもしれません。
- しかし、特定のアクセスパターンに依存したアドレスマッピングは汎用性がなく、要請が異なる他のアプリケーションとの同居が難しくなります。また、マスターがDDRへのマッピングを意識しなければいけなくなると、アーキテクチャ上の切り離せない仕様になってしまい他のシステムへの応用がし辛くなります。
- 万能解はないので、キャッシュを導入して不規則なランダム性を吸収したり、静的もしくは動的に柔軟なメモリマッピングが可能なメモリシステムを構成したりして、準最適解を作ることになると思います。なお、ページ機能はペナルティ条件を緩和する働きがあることを付け加えておきます(是非つけるべきです)。
考え方(マスターインターフェイス)
- DDRへのアクセス(上記のアクセスパターンのマッピング)が可能であれば、マスターの要求を受け付けるハンドシェーク制御にします。
- アクセスの単位は、DDRがバーストアクセスを基本していることから、クロック同期させると必然とバースト長4(DDR側が8)になります。なお、バーストにおいてWrapping対応[7]は難しくないのですが、ここでは簡単のため、バースト境界のアドレスは0に限定します。
- R/Wデータは、DDR規定のレイテンシ分遅れてアクセスすることになります。いずれも、Waitできないので制御を拒否することはできません。マスターの要求が通る=マスターは必ずR/Wを所定通りにアクセスしなければいけないことになります[8]。
- 上記から、規定のバスプロトコルを当てはめます。Requestインターフェイスはそのままで行けます。Read/Write Dataインターフェイスはそれぞれ、strb, flush信号が不要になります(DDRのバースト制御でハンドシェーク不可のため)。
考え方(DDRインターフェイス)
- DDRには固有のACタイミングがあり満足させなければいけません。しかし、全てのACパラメータを設定すると解釈が大変です。いくつかの単純なパラメータに集約することにします。
- 最初に簡単化のため、制限・制約を与えておきます。
- コマンド間には1サイクル以上のNOPを挿入
- バースト長は8固定
- バーストタイプはSequential(ここでは境界は切りの良い0とする)
- R/Wコマンドは必ずAuto Pre-charge機能を付ける(アドレス信号の10番はR/W時アサート)
- DDR3のBurst Chop機能は使用しない(アドレス信号の12番はR/W時アサート)
- ランダムアクセスの考え方は4サイクルのアクセスパターンをマッピングすることでした。この条件から、パラメータは以下に分類されます。そしてさらにR/Wによって細分化されます。つまり6つのパラメータが必要と言うことになります。
- パターンにおいて、コマンド発行からデータアクセスまでのレイテンシ
- マッピングにおいて、Activate間の間隔(同一バンク)
- マッピングにおいて、R/W間の間隔(RからW、WからRでデータの衝突を回避するため)
- ところで、マッピングのActivate間の間隔(異なるバンク)はR/Wに関係なく、以下の2つのパラメータが必要です。これらはmin条件です。
- Activateが2つ存在してもよい期間(つまりActivate間隔、Speedバージョンによっては6となり4つずつではなくなる)
- Activateが4つ存在してもよい期間(Activateが集中すると許容電流を超すための制限)
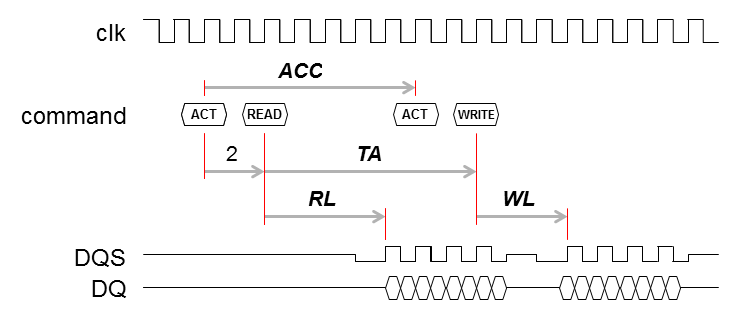
- 具体的な波形図を示しながら、具体的にパラメータ名を決めます(RL, WL, ACCR, ACCW, TARW, TAWR, RRD, FAW)。以下、参照するその他の変数[9]はDDRの仕様を参照して下さい。設定値は仕様書を理解すると算出できるのですが、ここで解説すると大変なので割愛します。
- ReadとWriteのレイテンシ設定として、RLとWLを用意
RL: AL + CL
WL: RL-1(DDR2), AL + CWL(DDR3)
- ACCはバンクごとのアクセス禁止間隔で、ReadとWriteの設定にACCRとACCWを用意
ACCR: 以下のうち最大のものを選ぶ
tRC
tRAS + tRP
2 + RL + BL + tRP
ACCW: 以下のうち最大のものを選ぶ
tRC
tRAS + tRP
2 + WL + BL + WR + tRP
- TAはR/W間のアクセス禁止間隔で、R→W用にTARWとW→R用にTAWRを用意(R→RとW→Wは不要)
TARW: RL - WL + BL + 1
TAWR: WL - AL + BL + tWTR
- Activateが2つ以上存在してはいけない期間設定に、RRDを用意(図中になし)
RRD: tRRD
- Activateが4つ存在してもよい期間用に、FAWを用意(図中になし)
FAW: tFAW - 2 x BL
考え方(DDR割込みアクセス)
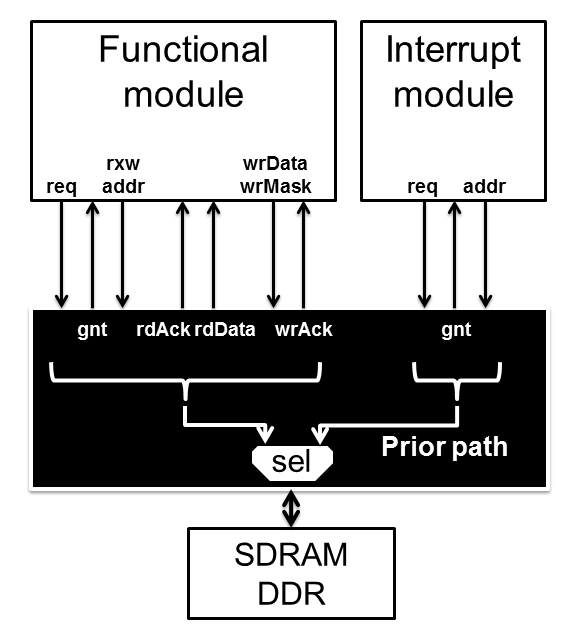
- DDRは電源投入後、初期化が必要になります。また、リフレッシュも必要です。これらは通常アクセスより優先します。従って、通常アクセスに割り込めるアクセスとして実装しなくてはなりません。
- 割り込みアクセスは通常アクセスのようなシーケンスパターンはありません。データ端子を駆動する必要はなく、単発のコマンドを発行するだけです。最終的な考え方として、通常アクセスと割り込みアクセスを2つのインターフェイスを用意し、割り込みアクセスを優先するようにします。
- 割り込みアクセスのインターフェイスは、端子情報を与えるだけなのでアドレス信号だけで十分ですRead/Write Dataインターフェイスは必要ありません。
- マスターインターフェイスと同様に、規定のバスプロトコルを当てはめます。Requestインターフェイスだけで十分であり、さらにrxw信号は不要です。
- 割り込みアクセスはコマンドだけなので、コマンド間の間隔のACタイミングを守るだけです。コマンドの種類によって値は異なるのですが、最大値を設定することにします。
- アクセス間隔ACCと対になる、COMを用意
COM: 以下のうち最大のものを選ぶ
tRC
tRFCmin
その他
- 上記はDDRを動かすための最低限の仕様になります。この先、もう少しあった方がいいものを箇条書きしたいと思います。キャリブレーションに関しては、DDR制御(実装)で述べたいと思います。
- 同一バンク、同一Rowへの連続アクセス時、Auto Pre-chargeを行わないページアクセスの実施
→前後のアクセスチェックと、Auto Pre-chargeもしくはPre-chargeの発行タイミング検討
- 低消費電力に必要なCKE制御
→アクセスの数サイクル前にCKEを操作する必要があり、細かなGated Clockを行うには要検討
- DDRの終端制御のためのODT制御
→端子のOE制御に近いため、そんなに難しくない
- ランク構成のための複数CS制御
→振り分け手法(アドレス等)検討と新たなTurn-around期間の追加が必要
- リフレッシュの自動化
→タイマーによる割込みアクセス検討
- DDR3のリセット端子対応
→タイミングには関係しないため、コントローラ内に無理して組み込まないでもよい
- また、DDR制御ではないのですが、In-orderで処理すると必ずACタイミングの制約(特に同一Bankアクセス)に引っかかり、無効なサイクルが生じます。シミュレーションして頂くと分かるのですが、ランダムアクセスでは何もしないと40%程度のスループット性能しかでません。
- マスターのアドレスをどのバンクに当てはめるかのメモリマッピングが重要になるとともに、複数候補の中からACタイミングに引っかからないアクセスを選び出すなどの工夫が必要[10]です。ここでは、注意点と言うことだけに留めておきたいと思います。
回路デザイン > 設計例 [DDR制御(論理)] > 目的・考え方 次のページ(実装にあたって) このページのTOP ▲
[6]
Activateコマンドは電力を多く消費します。R/Wを連続発行するだけのページ機能は低消費電力には有効な手段です。
しかしActivate状態を維持すると、同一バンクで異なるRowアドレスアクセスが来た場合、一旦メモリセルにデータを戻して再度取り直す必要があります。つまり、ペナルティが大きくランダムアクセスには不向きです。
mc2のP.9の右半分の波形を参照してもらうといいのですが、アクセスが同一バンクの同一Rowアドレスを判別してページアクセスする(これは当然ですね)ことと、アクセスがなくてもどこかのタイミングでPre-chargeする機能を組み込めばそこそこ両立できます。
ただし、このページで述べる割り込みアクセスがあれば、即座にページアクセスを中断しなければいけないことに注意して下さい。